What’s Happening Behind The Scene of a Rails Application

Jean-Michel Gigault
I have a continuous challenge in my job: put developers in the right conditions to understand what they are building and where their realisations stand in the Product. First and foremost the technical side.
Being an actual Web developer requires to be conscious at all times about where the code stands in the components’ architecture. Indeed, Rails is made for building final products without having to care about that and developers usually keep confused about how user’s requests are actually handled.
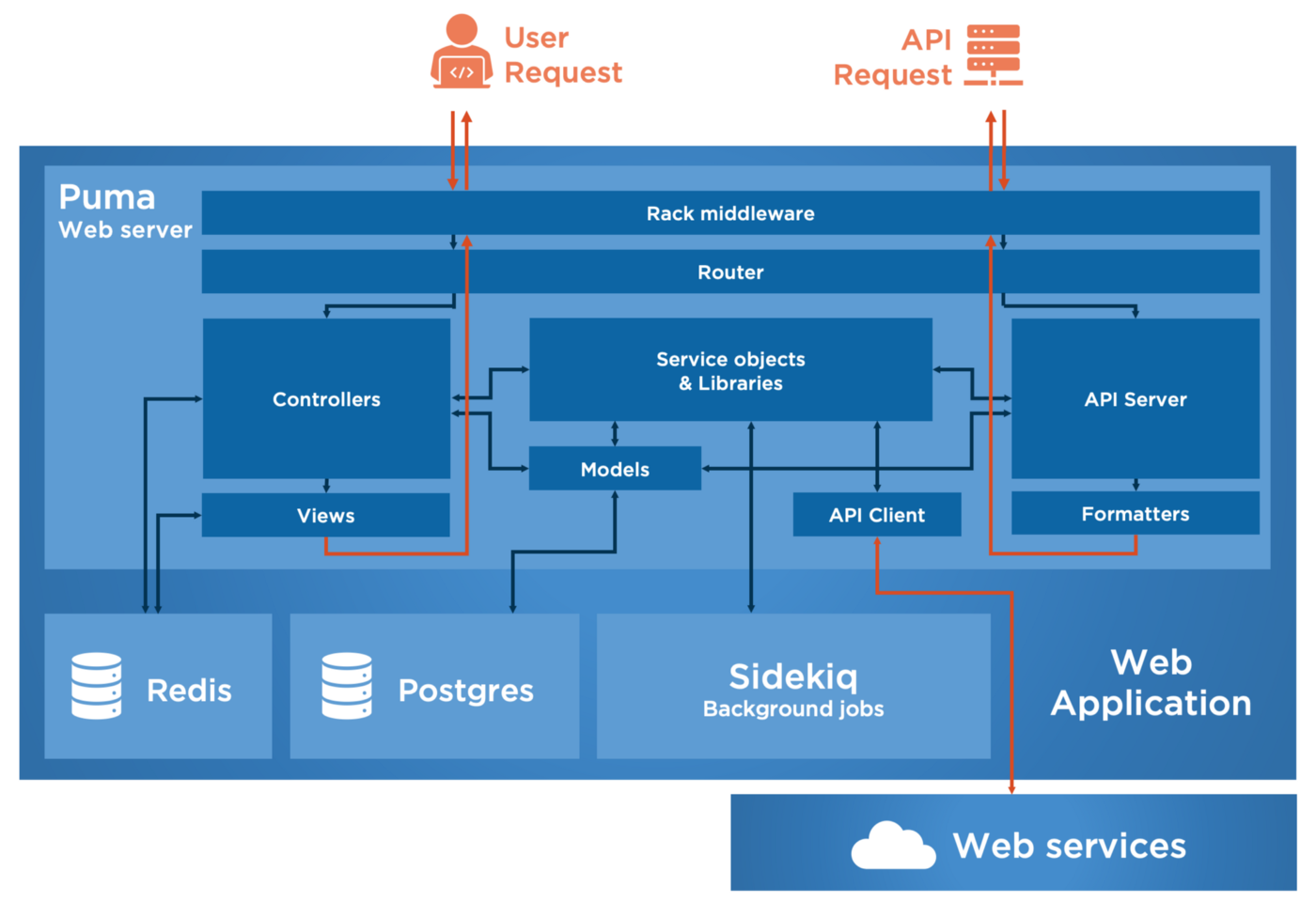
Main components of the architecture
Let’s have a look at all levels of the components’ stack and define their role. At first, let’s forget the Rails framework and focus on the surrounding environment.
Web server
The role of a Web server is to orchestrate the Unix-side of your Web Application. It keeps alive until you stop it and it cares about how to scale in terms of memory and CPU usage. It is the front office of all HTTP requests before they actually interact with Rails.
Its configuration answers those kinds of question:
- How many visitors are supposed to be handled at the same time by a single instance of your application?
- How the application is supposed to handle signals of the host machine (start, stop, rage quit, etc)?
- Which HTTP ports the application is supposed to listen to?
Puma is the default Web server of a Rails app. It’s standing behind the command «rails server» until you change the configuration. Therefore it is one of the most flexible Web servers for Ruby and Rack applications because it scales in two different manners called “threads pool” and “clustered mode”, allowing you to get the advantage of both available memory and CPU cores of the environment.
It’s worth noticing that when you deploy your Web Application, what we call here a “Web server” may in fact takes the role of an Application server. For instance, Heroku handles requests through its own Web servers and then forwards them to your application. This is best explained by such article.
Background jobs
Because the Web is asynchronous, background jobs are optional but usually required to build a scalable Product. Their role is to handle all processes that are not supposed to render End-User’s content such as HTML pages. For instance: export data into Excel files, send mails or synchronise data with external services.
In Rails, background jobs are handled through Active Job framework, and depending on the use cases you would like to plug a dedicated backend like Sidekiq or Resque. The choice of a backend mainly depends on the running environment (available databases, memory usage, etc.) and the way you want to handle queuing and concurrency.
I suggest you to read this brief article written by my colleague: Benchmarking Excel Generation In Ruby And How To Avoid Background Jobs Memory Explosion!
Databases
Except if your Web Application is a simple Landing Page that displays static information, the role of databases is to build advanced stories. It allows you to store user’s input and create something else with it that can later be rendered to the same user or even other users. Indeed, databases are made for all features that need to go further than the scope of a single user’s session: Keeping a shopping cart into memory for multiple days or sharing user’s data with others.
PostgreSQL is an advanced open-source relational database with a large set of SQL-compliant capabilities and extensions built by the community. You would build applications on top of a relational database like PostgreSQL when you need to store multiple scheme of structured data and build features based on top of their relationships. For instance linking articles, prices, clients and invoices within an e-commerce solution.
Redis is more likely a “dictionary” or a “hash table” based on the key-value storage paradigm. It allows you to store a set of data structures with an optional durability. It fits perfectly with caching purposes because of its expiry capabilities and fast data retrieval performance. In Rails, you would also use this kind of database to handle advanced features based on user’s session like a history of navigation, filtering ans search options, different modes of navigation.
Web services
Today, a common way of building applications is to rely on a Cloud environment. The role of Web services is to help you building final products by focusing on your added value. It brings your Web Application the components that you are not efficient to deliver by yourself.
For instance, when you build an e-commerce you would choose an external Web services to handle the payment means. Because you’re not a banking service. When you deploy on PaaS solutions like Heroku, you would choose to forward your access logs to an addon like Sumo-Logic. Because you’re not efficient in digesting a log trace.
Most of the popular Web services provide you with libraries packaged in Gems, in order to quickly and easily interact with their systems.
Rack Middleware
It’s important to understand that what makes Rails a Web framework is Rack. Indeed, Rails is built on top of the Rack framework.
The role of Rack is to handle the HTTP protocol on which Web Applications are based. HTTP describes how to share octets between two machines and Rack translates them into comprehensive structured Ruby objects for Rails: The request and the response, headers and parameters, settings of cookies and session, etc.

A Rack middleware is a component that handles one specific part of the user’s request and/or Rails’ response.
They are stacked in a given order, determined at the initialisation step of the application and they are linked together like Russian dolls. Each middleware is supposed to do one single thing, call the next middleware of the stack and then return its result to its parent.
class MyMiddleware
def initialize(app)
@app = app
end
def call(env)
# do something before calling the next middleware
puts "My name is Rack middleware"
# then call the next middleware and return its response
@app.call(env)
end
end
At the end of the stack comes the router of the Web Application (explained in the next section), as you can see by running the command rails middleware:
$ rails middlewareuse Webpacker::DevServerProxy
use Rack::MiniProfiler
use Rack::Cors
use Rack::Sendfile
use ActionDispatch::Static
use ActionDispatch::Executor
use Rack::Runtime
use Rack::MethodOverride
[...]
use Rack::ConditionalGet
use Rack::ETag
use Rack::TempfileReaper
use Rack::Attack
use Warden::Manager
run MyRailsApplication.routes
One of a great middleware is Rack::Attack. Its role is to block abusive requests to avoid your application from being overloaded during a DoS attack, for instance. When the IP address of a request is recognised as being abusing (based on number of requests per period of time), it decides not to call the next middleware but to render immediately an error response. It breaks the chain and consequently increases the performance to handle such abusive requests.
Other examples of use cases:
- Rack::Cors handles Cross-Origin Resource Sharing settings in the response to tell the browser about the authorized AJAX calls on cross domains.
- Apartment’s Elevators handle the strategy to determine which tenant is concerned by the user’s request within a multi-tenancy application.
- A custom middleware that blocks requests and renders a proper message when the application is put in maintenance mode.
Some of you may ask the difference between Rack middleware and Rails controllers’ callbacks like before_action because both allow you to build logic around an action.
The main difference stands in their position in the components’ stack regarding the router: Rack middleware takes place before the route is determined, so that it is always involved whenever the requested route is not supposed to be handled by an internal controller.
For instance, when routes are handled by Rails Engines like Devise, Grape or Sidekiq Web UI. The scope of Rack middleware is always “greater” than Rails’ controllers.
The router
The role of the router is to declare which URLs and HTTP request methods are available in your Web Application, and map them with controllers’ actions.

For instance, it determines which action is involved when making a GET request to the URL /users. And even if the convention implies UsersController#index, you must explicitly declare your routes in the configuration file router.rb, either by using helpers or manual declarations:
# using helper
resources :users, only: [:index]
# manual declaration
get '/users', to: 'users#index', as: 'users'
This is also the place where to declare the Rails Engines. A Rails Engine is an embedded Rack application that extends the capabilities of your application. One of the most popular one comes with Devise as a complete MVC solution to handle user’s registration and sessions:
# mounting Devise's Engine in router.rb
devise_for :users
Controllers and MVC pattern
It’s well known, Rails framework is based on the architectural pattern called model-view-controller.
Controllers handle user’s requests (for instance “get the list of active users”), interact with Models (for instance “retrieve User records with an active flag from database”) and respond to the user by rendering Views (for instance “build an HTML content with a title and a table of users”).
Contrary to what’s shown in the diagram at the beginning of the article, views are not the final point before going back to the Rack middleware’s stack. They stand in the scope of controllers, and controllers can still perform a lot of things after rendering them. For instance, when you declare “after” and “around” action callbacks.
A great use case comes with Pundit’s verification callbacks that aim at adding a security layer regarding the permissions of the current user. Those verification run after the view is rendered. Also think about controllers’ actions that do not even interact with proper views from the folder “app/views/”. For instance when you render a JSON object in API contexts or even when you render No Content HTTP request.
Therefore, the role of controllers is to build and return a response Object that can then be handled by Rack middleware’s stack, in the reverse order (think Russian dolls). At the end of the stack, when each middleware has returned the response Object to its parent caller, the response is formatted in raw HTTP-compliant octets by Rack and sent back to the user through the Web server.
Service Objects, libraries and more
There are many different design patterns to orchestrate what’s happening inside controllers and help you organise your code into maintainable sub-components, in opposition to writing the whole logic right into controllers’ actions.
A popular approach is to use the Service Objects design pattern, consisting in embedding the logic of a given action into a dedicated Ruby object. By building a collection of Service Objects with their own responsibilities and interactions, you can then build advanced features shared across the application through multiple controllers or even other layers (as shown in the diagram with the API Server).
Service Objects or what else you use to embed your logic may also interact with libraries such as Slack Ruby Client whose you don’t own the code. A good approach while using external libraries is to recreate your own local interface that embeds the specific pieces of code. For instance having a generic object called “Notifier” that embeds Slack-specifics will help you migrating your Web Application if you plan to change Slack by MS Teams using MS Teams Ruby Client.
API Server
The Rails framework is made for building Web Applications and API servers in a reversible way. Controllers have builtin features to handle multiple formats at once in the same place and you can render HTML content for real users or JSON content for machines within the same controller’s action.
But in some circumstances, you may choose to extract the API context into a separate layer of the application such as in a Rails Engine like Grape. The router is therefore in charge of forwarding requests to the relevant layer. For instance, you can mount a Grape API in a namespace /api and consider all sub-URLs to be in handled by it.
Depending on the scale of your Product, you would better consider having dedicated Web servers for each Web and API context, so that you can adapt hardware and software components to best comply with their specific usage.
Formatters and presenters
As referred above, your Web Application may have to handle multiple formats of requests and responses depending on the caller. This is the role of formatters, also known as “presenters” in some design patterns.
Depending on the Accept header of a request, your Web Application can format the response’s content using different formats like JSON, JSONAPI, CSV, XML, and of course HTML.
API Client
API Client is the layer of your application that aims at requesting external Web services. For instance to retrieve the weather forecast for a tourism website or to send scheduled notifications through a mailer service.
An API Client is not supposed to know about your internal database schema, your models or even any business rule, its single role is to know how to authenticate and communicate with external web services and fetch/pull data for your service objects.
A good approach is to wrap them all into a common interface object, so that you can implement shared logic such as logging, monitoring, switch on/off during maintenance periods, etc…